











-

Aura Walden review: probably the best digital frame available
The Walden is Aura's biggest, priciest and best digital photo frame available for shoppers in the US.
-
-

Nutribullet Ultra blender review
The Nutribullet Ultra is designed to be super-powerful but also super-quiet. Here's my review.
-

Bob & Brad D6 Pro massage gun review: Elite-tier percussive massage support
The D6 Pro is an excellent massage gun that, once you’re used to it, can be a great way to alleviate aches and pains.
-

Aura Carver Mat review: a gorgeous but flawed digital photo frame
This 10-inch digital photo frame by Aura looks the part and is super easy to use – but it isn't perfect
-

Ricoh GR IIIx review
The Ricoh GR IIIx offers a new twist on the GR III, thanks to its 40mm f/2.8 lens. Does this make it the ultimate street shooter?
-

Sony Cyber-shot RX100 VII review
The RX100 VII delivers great images, crisp videos and stellar AF performance, but it's hard to get past the price tag.
-

Ninja Double Stack air fryer review: half the footprint, double the fun
Ninja's innovative Double Stack air fryer is designed for those with small kitchens but big appetites, and it really delivers.
-







How TechRadar tests

Product testing for the real world
You need to know that the device or service you’re about to spend money on works as advertised - and that it works in the real world.
- We test properly: objective and subjective testing
- We use experienced experts for our reviews
- We always offer 100 per cent unbiased, independent opinions
reviews
hours' testing
buying guides
-

Verizon's Google Pixel 8a deal gets you this brand new device for free with no trade
Thinking about picking up the Google Pixel 8a? Verizon's opening deal gets you the device for free without the need for a trade.
-
-
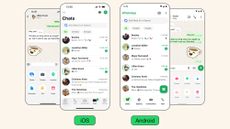
What's happened to WhatsApp? A big redesign is rolling out now – here's what's new
WhatsApp has been redesigned to be "fresh, simple and approachable", and everyone should get the update.
-
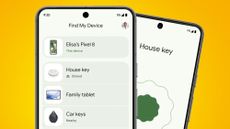
Google’s Find My Device network seems to be slowly rolling out in the UK and beyond
The long-delayed Android Find My Device network could be globally available soon.
-

Android 15 tipped to get a video stabilization upgrade to match the best of iPhone
Android 15 could bring in a video stabilization upgrade for third-party apps.
-
 TechRadar deals
TechRadar dealsThe best Mint Mobile phones for 2024
These are the top Mint Mobile phones you should consider buying.
-

Google Pixel 8a: price, features, specs, and everything you need to know
The Google Pixel 8a is a mid-range alternative to the Pixel 8. Here's what you need to know about it.
-

Finding your offline Google Pixel 8 on Android's Find My Device network might be harder than we thought
You can find your offline Google Pixel 8 on Android's Find My Device network, but there are several restrictions.
-







-

It's been a bad week for public cybersecurity
Ransomware attacks have meant that hospitals are fighting infections both in their wards and in their computer systems.
-
-

Microsoft could turbocharge Edge browser’s autofill game by using AI to help fill out more complex forms
GPT-4 is set to power Microsoft Edge’s enhanced autofill feature, promising a smarter browsing experience.
-

iTunes for Windows 11 gets a fresh update with a vital security fix, and it brings in support for new iPad Air and iPad Pro
Apple has released iTunes 12.13.2 for Windows, complete with an important security fix, and support for new iPad models.
-

Windows 11’s Copilot AI just took its first step towards being an indispensable assistant for Android – but Google Gemini hasn’t got anything to worry about yet
Windows 11’s Copilot could become way more useful for Android owners – let’s hope iPhones aren’t left out in the cold.
-

Nvidia could use massive 600W-capable cooler for RTX 5090 – but don't panic about flagship GPU being a power hog
New purported photos of Nvidia Blackwell prototypes show off some huge coolers.
-

Microsoft might be trying to sneak Bing into one of Windows 11’s apps – and some users won’t be happy
Need more Bing in your life? Snipping Tool users in Windows 11 might be getting just that, like it, or perhaps not...
-

NYT Wordle today — answer and hints for game #1056, Friday, May 10
Looking for Wordle hints? We can help. Plus get the answers to Wordle today and yesterday.
-







-

Apple's price cut on the iPad 10.9 is not as good as it seems - here's why
Apple has announced a permanent price cut to the iPad 10.9 so is it worth buying or are there better ways to spend your money on a budget tablet?
-
-
iTunes for Windows 11 gets a fresh update with a vital security fix, and it brings in support for new iPad Air and iPad Pro
Apple has released iTunes 12.13.2 for Windows, complete with an important security fix, and support for new iPad models.
-

Apple scraps iPad Pro 'Crushed' ad and issues rare apology – and it was the right thing to do
The iPad Pro 'Crushed' ad raised hackles among creatives and now Apple has apologized and scrapped plans for a TV run.
-

The best iPad deals in May 2024
These are all of the best iPad deals that are available now so you can pay the lowest price for one of Apple's premium tablets.
-

The best MacBook deals in May 2024
Our roundup of all the best MacBook deals so you can pay the lowest price for one of Apple's premium laptops.
-




-
 EXCLUSIVE
EXCLUSIVEKingdom of the Planet of the Apes director explains the film's timeline, setting and cinematic universe
TechRadar sat down with Kingdom of the Planet of the Apes director Wes Ball to discuss the new movie's timeline, setting and cinematic universe.
-
-

Ted season 2 is officially coming to Peacock – no surprise, since it's the streamer's most-watched original show
Seth MacFarlane's potty-mouthed pal is coming back for a second season.
-

'I love this show... but it’s not a musical': Doctor Who season 14 showrunner on Disney Plus debuts and the iconic sci-fi series' latest regeneration
Returning Doctor Who showrunner Russell T. Davies takes TechRadar inside the iconic sci-fi show's TARDIS-sized rebook.
-

7 new movies and TV shows to stream on Netflix, Prime Video, Max, and more this weekend (May 10)
From returning sci-fi series to critically acclaimed sports dramas, there’s plenty to watch this weekend.
-

Prime Video movie of the day: Cocaine Bear is the best film about a bear on cocaine you'll watch today
Turn off your brain, turn up your soundbar and enjoy this delightfully silly horror comedy.
-





-
-
 Updated
UpdatedThe best 120Hz 4K TVs 2024
Next-gen console owner? A TV with an HDMI 2.1 port will unlock its true 120fps potential. Here are our best 120Hz 4K TV picks.
-
 Hot deals
Hot dealsThe cheapest OLED TV deals and sales for May 2024
Your guide to the best OLED TV deals with incredible sales from brands like Sony, LG, and more.
-
 Updated
UpdatedThe best 65-inch TV 2024
We pick out the best 65-inch 4K TVs to complete your home theater setup, no matter how much you want to spend.
-

The best Mother's Day gift ever: Samsung's The Frame TV drops to a record-low price
Samsung's gorgeous The Frame TV might just be the best Mother's Day gift ever and it's on sale for a new record-low price.
-

The best 4K Blu-ray players 2024
Streaming services are popular, but there's no better way to watch movies than with the best 4K Blu-ray players.
-
 Updated
UpdatedThe best 75-inch TVs 2024
The best 75-inch TVs offer a true big-screen experience, with a size befitting the greatest films and the most nail-biting sports matches.
-
 Updated
UpdatedThe best soundbars for 2024
From budget-friendly bars to Dolby Atmos wonders, the best soundbars make it easy to get a serious TV audio upgrade.
-







-
-

'These team conversations have been tough' – Sonos power-users really don't like its new app, and the company responds, including asking for feedback
A new, updated Sonos app has rolled out to iOS and Android users, but it’s missing many of the features that customers had come to rely on.
-
 Updated
UpdatedThe best turntables 2024
The best record player is just a few clicks away, whether you're a vinyl veteran or a turntable newbie.
-

I saw Loewe’s new Bluetooth speaker collab with Kylian Mbappé, and it's a hat trick of striking colors for this Sony and JBL rival
Loewe scores Mbappé collaboration to launch a special edition Bluetooth speaker of its We Hear range, with a trio of new colors, more power and battery life.
-

Sennheiser's new wired headphones look like comfortable audiophile cans ready for travel
The HD 620S takes cues from the HD 600 and 500 lines for a well-performing, yet comfortable pair of headphones.
-
 Updated
UpdatedSonos Ace headphones: what we know from leaks so far
The first Sonos headphones are rumored to arrive very soon.
-
 Updated
UpdatedThe best over-ear headphones 2024
Looking for the best-sounding headphones? These are the cans you need to get the most out of your music.
-

Technics’ turntable collab with Lamborghini brings new meaning to the phrase ‘direct drive motor’
Technics has worked with Lamborghini on a motoring-inspired design of its popular SL-1210MK7 DJ turntable.
-







-
-

We probably won’t see an Oura Ring 4 anytime soon, according to Oura's CEO
Oura announces two new features for the Oura Ring Generation 3, as its CEO implies we won't see a Gen 4 soon.
-
Bob & Brad D6 Pro massage gun review: Elite-tier percussive massage support
The D6 Pro is an excellent massage gun that, once you’re used to it, can be a great way to alleviate aches and pains.
-

This new temperature-regulating, snore-detecting mattress cover definitely wasn’t on my 2024 bingo card
Two years after launching the Pod 3 smart mattress cover, Eight Sleep are back with new Pod 4 and Pod 4 Ultra models
-


-
-

GoPro Max 2 officially delayed – which means the Insta360 X4 remains the best 360-degree camera you can buy
In GoPro's quarterly earning call, CEO Nick Woodman confirms Max 2 is delayed, but new products are in the works for 2026.
-
 Updated
UpdatedBest Sony lenses 2024: top lenses for Sony mirrorless cameras
If you've got a Sony mirrorless camera, these are the lenses you need to know about.
-

“We do not view AI-generated images as photographs” – photo contest experts talk AI, and the steps they're taking to spot fake photos
Photography contests are adapting to the explosion of AI by modifying their rules and employing multi-layered approaches to spot fake and manipulated images.
-

Our favorite Sony camera has a massive $400 off in this cashback deal
Sony rebates have knocked $400 off the Sony A7R V, $300 off the Sony ZV-E1 and $200 off the Sony A7 IV at leading retailers.
-




-
-

Aura Walden review: probably the best digital frame available
The Walden is Aura's biggest, priciest and best digital photo frame available for shoppers in the US.
-
Nutribullet Ultra blender review
The Nutribullet Ultra is designed to be super-powerful but also super-quiet. Here's my review.
-

Matter 1.3 pushes the standard into your kitchen, laundry room, and garage
Matter's latest update adds support for more appliances and features like the ability to finally set Scenes.
-
Aura Carver Mat review: a gorgeous but flawed digital photo frame
This 10-inch digital photo frame by Aura looks the part and is super easy to use – but it isn't perfect
-


-
 Updated
UpdatedThe best turntables 2024
The best record player is just a few clicks away, whether you're a vinyl veteran or a turntable newbie.
-
-
Updated
The best 120Hz 4K TVs 2024
Next-gen console owner? A TV with an HDMI 2.1 port will unlock its true 120fps potential. Here are our best 120Hz 4K TV picks.
-
Updated
Best Sony lenses 2024: top lenses for Sony mirrorless cameras
If you've got a Sony mirrorless camera, these are the lenses you need to know about.
-
 Buying guide
Buying guideBest FPS games - essential first-person shooters
Our pick of the best FPS games you can play right now on console and PC, including Titanfall 2 and DOOM Eternal.
-
Updated
The best over-ear headphones 2024
Looking for the best-sounding headphones? These are the cans you need to get the most out of your music.
-

The best earbuds 2024
Our pick of the best earbuds, including wired, wireless and true wireless devices.
-
 Updated
UpdatedThe best phone 2024
We've tested the best phones around, in every price range, to bring you this definitive ranking of the best smartphone to buy.
-




Why we're experts

We care passionately about tech
The TechRadar team has a life-long passion for the latest innovations – over 300 years of experience between us, in fact – and we’ve made it our mission to share that combined knowledge and expertise with you.
We’re here to provide an independent voice that cuts through all the noise to inspire, inform and entertain you; ensuring you get maximum enjoyment from your tech at all times. Technology is our passion, so let us be your expert guide.
years' experience
how-tos written
Apple events covered
-
-
 VPN deal
VPN dealSurfshark just made its prices even cheaper
The best cheap VPN just got cheaper, slashing its fees up to 86% and adding extra perks. Bargain aside, here's why Surfshark is worth getting.
-

Verizon's Google Pixel 8a deal gets you this brand new device for free with no trade
Thinking about picking up the Google Pixel 8a? Verizon's opening deal gets you the device for free without the need for a trade.
-

Apple's price cut on the iPad 10.9 is not as good as it seems - here's why
Apple has announced a permanent price cut to the iPad 10.9 so is it worth buying or are there better ways to spend your money on a budget tablet?
-

Best Buy's having a huge sale ahead of Memorial Day - 17 deals I'd buy now
Best Buy is having a huge weekend sale ahead of Memorial Day, and I'm rounding up the 17 deals I would buy right now.
-

New iPad preorders - where to buy Apple's 2024 Pro and Air tablets
Apple has announced the new iPad Pro and iPad Air – here's where you can buy both tablets, including preorder deals and trade-in offers
-

Best Buy Memorial Day sale 2024: all the best early deals
Your guide to the Best Buy Memorial Day sale with all the latest news, early deals and our expert predictions for this year's event.
-






-
-

Hostinger Coupon Codes for May 2024
Browse the latest Hostinger coupon codes for savings on a range of web packages, from shared web to VPS hosting.
-
Google Workspace Coupon Codes for May 2024
These Google Workspace coupon codes are here so you can make bigger savings on your plan.
-

Casper Coupons for May 2024
These Casper coupons can help you save big on your next bedding purchase from sheets, pillows, mattresses, and more.
-
Keeper Security Promo Codes for May 2024
Look through our Keeper Security promo codes to save on subscriptions to the online password manager and protect your details online for less.
-




TechRadar's story

Our mission is unchanged
TechRadar was launched in January 2008 with the goal of helping regular people navigate the world of technology. It quickly grew to become the UK's biggest consumer technology site.
Expansions into the US and Australia followed in 2012 and we are now one of the biggest tech sites in the world.
- We've been covering tech since 2008
- 17 international editions from Mexico to New Zealand
- We're a globally respected brand worldwide
-
-
Microsoft could turbocharge Edge browser’s autofill game by using AI to help fill out more complex forms
GPT-4 is set to power Microsoft Edge’s enhanced autofill feature, promising a smarter browsing experience.
-
iTunes for Windows 11 gets a fresh update with a vital security fix, and it brings in support for new iPad Air and iPad Pro
Apple has released iTunes 12.13.2 for Windows, complete with an important security fix, and support for new iPad models.
-
Windows 11’s Copilot AI just took its first step towards being an indispensable assistant for Android – but Google Gemini hasn’t got anything to worry about yet
Windows 11’s Copilot could become way more useful for Android owners – let’s hope iPhones aren’t left out in the cold.
-
Microsoft might be trying to sneak Bing into one of Windows 11’s apps – and some users won’t be happy
Need more Bing in your life? Snipping Tool users in Windows 11 might be getting just that, like it, or perhaps not...
-
-
-
 Buying Guide
Buying GuideBest handheld games consoles in 2024
If you're in the market for a handheld games console, these are our top recommendations.
-

Evil Empire delays The Rogue Prince of Persia so players can "have their fun" with Hades 2
The Rogue Prince of Persia has received a last-minute delay to avoid clashing with Hades 2.
-
 VPN
VPNBest VPN for Valorant in 2024
I've tested tons of VPN services to find the best picks for gaming (and your Valorant match). Here's how a VPN can give you the edge online.
-

Lords of the Fallen and Sniper Ghost Warrior Contracts 2 are set for an Xbox Game Pass release this year
Microsoft has signed a deal to bring Lords of the Fallen and Sniper Ghost Warrior Contracts 2 to Xbox Game Pass.
-




Between them, the TechRadar team have 300 years' experience in tech journalism. Here's why you should trust them.


















-
-
VPN deal
Surfshark just made its prices even cheaper
The best cheap VPN just got cheaper, slashing its fees up to 86% and adding extra perks. Bargain aside, here's why Surfshark is worth getting.
-
 Updated
UpdatedBest free PDF readers of 2024
We've been testing the best free PDF readers - here's what we learned and why we loved these top-rated programs.
-
 Updated
UpdatedBest laptops for photo editing of 2024
We tested the best laptops for photo editing - and are our top picks for photographers, artists, and designers who want pixel-perfect pictures.
-

Developers say they need better tech in order to innovate - but many aren't sure where it will come from
Developers are spending too much time troubleshooting to innovate, but AI might not be the only solution.
-


