









-

Ninja Double Stack air fryer review: half the footprint, double the fun
Ninja's innovative Double Stack air fryer is designed for those with small kitchens but big appetites, and it really delivers.
-
-

reMarkable 2 review: still the best e-paper note-taking device money can buy
If you love to sketch and jot down notes, there’s no better e-paper tablet than the reMarkable 2, but that’s all it’s good for.
-

iPad Air 13-inch (2024): You no longer need to go Pro
With the iPad Air (2024), Apple adds all new size. Here's our first impressions of the 11-inch and 13-inch iPad Air with M2.
-

Fujifilm Instax mini 99 review: Instant fun!
The Instax mini 99 is an exciting new option for fans of film photography who want to get creative.
-

Shark HydroVac Cordless review: a very effective vacuum-mop
We take a closer look at the cordless Shark HydroVac, to see if it can achieve spotless results with little elbow grease.
-

Rabbit R1 AI companion: An adorable but half-baked idea that you can ignore
Rabbit R1 is an ultimately frustrating mobile AI device that offers no incentives to leave your phone behind.
-
 Review
ReviewEngwe P275 Pro review: A powerful city e-bike with automatic gear shifter
With branded parts and slimmed down design, the Engwe P275 Pro is a clear gear change for this bike producer.
-







How TechRadar tests

Product testing for the real world
You need to know that the device or service you’re about to spend money on works as advertised - and that it works in the real world.
- We test properly: objective and subjective testing
- We use experienced experts for our reviews
- We always offer 100 per cent unbiased, independent opinions
reviews
hours' testing
buying guides
-

The Google Pixel 8a is here - and yes, you can already get it for free with this deal
The latest Google Pixel 8a offers a compelling array of specs for a wallet-friendly mid-range price.
-
-

Quick! The Google Pixel 8 Pro is $440 off at Mint Mobile right now - the lowest price yet
This Pixel 8 Pro deal at Mint Mobile won't last - it's the cheapest upfront price yet without the need for a pesky trade-in.
-

The iPhone 17 line could include huge upgrades and a new Slim model
A smaller Dynamic Island, a more complex design, and loads of RAM could all be planned for the iPhone 17 series.
-
Rabbit R1 AI companion: An adorable but half-baked idea that you can ignore
Rabbit R1 is an ultimately frustrating mobile AI device that offers no incentives to leave your phone behind.
-

Google Pixel 9 case leak shows we may get three models
Cases for the Pixel 9 are showing up already, and back up previous rumors around the flagship phone series.
-

Leaked iPhone 16 case molds hint at MagSafe upgrades this year
The MagSafe charging standard hasn't changed much since 2020, but 2024 could be the year for an upgrade.
-

iPhone 16 Plus: latest news, rumors and everything we know so far
There are now numerous iPhone 16 Plus leaks, and you'll find them all here.
-






-

Huge leak of next-gen Asus gaming laptops suggests just how powerful Strix Point CPUs could be
Asus has leaked its upcoming next-gen gaming laptops, with various models spotted online.
-
-
Quordle today – hints and answers for Wednesday, May 8 (game #835)
Looking for Quordle clues? We can help. Plus get the answers to Quordle today and past solutions.
-

NYT Wordle today — answer and hints for game #1054, Wednesday, May 8
Looking for Wordle hints? We can help. Plus get the answers to Wordle today and yesterday.
-

NYT Strands today — hints, answers and spangram for Wednesday, May 8 (game #66)
Looking for NYT Strands answers and hints? Here's all you need to know to solve today's game, including the spangram.
-
Google is working on a faster Android setup process that uses Wi-Fi and a cable
A deep dive into Google’s Data Restore Tool showed two features allowing fast transfer speeds and easy file restoration.
-
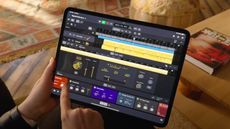
The 5 subtle AI announcements Apple made at its big iPad 2024 launch event
Beneath the glitzy product announcements at Apple's 2024 iPad event, there was some uncharacteristic AI chatter.
-
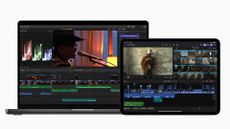
Apple's new Final Cut Pro apps turn the iPad into an impressive live multicam studio
Users can watch feeds from four different iPhones although each mobile device will need the new Final Cut Camera app.
-






-

iPad Air 13-inch (2024): You no longer need to go Pro
With the iPad Air (2024), Apple adds all new size. Here's our first impressions of the 11-inch and 13-inch iPad Air with M2.
-
-
The 5 subtle AI announcements Apple made at its big iPad 2024 launch event
Beneath the glitzy product announcements at Apple's 2024 iPad event, there was some uncharacteristic AI chatter.
-
Apple's new Final Cut Pro apps turn the iPad into an impressive live multicam studio
Users can watch feeds from four different iPhones although each mobile device will need the new Final Cut Camera app.
-

Apple iPad Pro M4 event Live blog as it happened: OLED, Air, Pencil and more
Our live blog of Apple's 'Let Loose' event, tracking news as it happened on the biggest day for the iPad since it launched.
-

The new Magic Keyboard for the freshly debuted iPad Pro will power up your iPad experience with style and function
Apple unveils sleek iPads, M4 chip, and upgraded accessories including a redesigned Magic Keyboard for enhanced functionality at May 7 “Let Loose” event.
-



-
 Updated
UpdatedThe best Martin Scorsese movies: every film ranked from worst to best
TechRadar ranks the best Martin Scorsese movies from worst to best, including Killers of the Flower Moon.
-
-

Wednesday season 2 adds Doctor Who, Star Wars, and Addams Family movie actors to its cast as filming gets underway
The hugely popular Netflix series has received a big cast update as principal photography begins on its second season.
-

Prime Video movie of the day: Hellraiser III: Hell on Earth is a hellishly good time
The ultra-gory horror franchise returns for a third instalment with even more violence than before
-

Netflix movie of the day: Mr and Mrs Smith delivers killer chemistry from Angelina Jolie and Brad Pitt
Not so much an action movie as a romcom with assault rifles.
-

Star Wars: The Acolyte trailer breakdown: 5 things you might have missed
The new suspense-filled trailer for Star Wars' next TV show arrived on May 4 – here are five things you probably overlooked.
-





-
-
 Hot deals
Hot dealsThe cheapest OLED TV deals and sales for May 2024
Your guide to the best OLED TV deals with incredible sales from brands like Sony, LG, and more.
-
 Updated
UpdatedThe best 65-inch TV 2024
We pick out the best 65-inch 4K TVs to complete your home theater setup, no matter how much you want to spend.
-

The best Mother's Day gift ever: Samsung's The Frame TV drops to a record-low price
Samsung's gorgeous The Frame TV might just be the best Mother's Day gift ever and it's on sale for a new record-low price.
-

The best 4K Blu-ray players 2024
Streaming services are popular, but there's no better way to watch movies than with the best 4K Blu-ray players.
-
 Updated
UpdatedThe best 75-inch TVs 2024
The best 75-inch TVs offer a true big-screen experience, with a size befitting the greatest films and the most nail-biting sports matches.
-
 Updated
UpdatedThe best soundbars for 2024
From budget-friendly bars to Dolby Atmos wonders, the best soundbars make it easy to get a serious TV audio upgrade.
-

Samsung's new, cheaper OLED TVs are now available to buy
Samsung's entry-level S85D series has arrived, providing a less expensive OLED TV option that still offers premium features.
-







-
-

Sennheiser's new wireless earbuds are packed with features, but cheaper than Sony, Bose and AirPods Pro
Sennheiser's Accentum True Wireless are smartly priced earbuds in a competitive headphones market – but should you buy them?
-

Focal's new headphones take different approaches to immersive audio
The Azurys pair sport an closed-ear design to isolate sound while the Hadenys is open-ear enabling better immersion.
-

I thought screens on earbuds cases were a bit meh – but JBL just proved me wrong
JBL Live Beam 3 arrived with two other screen-enhanced options in January – and it's a nice upgrade on the Tour Pro 2 case.
-

Fake AirPods: how to spot if your Apple headphones are the real deal
Are your Apple AirPods legit? Here are the signs that will reveal if your earbuds are what they say they are.
-

How to connect your AirPods to an Xbox
Find out how to connect your AirPods to an Xbox Series X/S or One in just a few minutes in this step by step guide.
-

Sennheiser Accentum Plus vs Bose QuietComfort 45: which headphones should you buy?
Sennheiser’s new Accentum Plus headphones are impressive – but can they compete with the beloved Bose QuietComfort 45s?
-

Beats Solo 4 review: a solid update to an iconic pair of wireless headphones, but the competition is now too hot
Beats' successor to the Solo 3 on-ear wireless headphones offer extended battery life and extra features – but are the improvements enough when other headphones are so good?
-







-
-

Samsung Galaxy Watches (and the Galaxy Ring) could get an AI-powered heart health upgrade
Samsung's latest patent could be big news for anyone wanting to take a more comprehensive picture of their heart health.
-

Smart ring vs smartwatch: Which fitness tracking wearable is best for you?
Anyone who tells you smart rings are always the better choice haven't tested many of them.
-

I tried this Iron Man-style exoskeleton for a day, and it's so good I'll keep using it
An exoskeleton with assistance and workout modes that makes running, especially uphill, a whole lot easier.
-



-
-
Fujifilm Instax mini 99 review: Instant fun!
The Instax mini 99 is an exciting new option for fans of film photography who want to get creative.
-
 Updated
UpdatedBest Sony camera 2024: the top choices for both stills and video
Searching for the best Sony camera? Whether you need a full-frame powerhouse or a travel-friendly compact, we've ranked the best models in its impressive range.
-

This AI 'poetry camera' shoots haikus instead of photos – and that’s way more interesting than megapixels
This Instax-like camera is like a reverse AI image generator – image-to-text – printing words instead of pictures
-

I used my DSLR for the first time in years since switching to mirrorless – here's four things I learned
TechRadar's Cameras Editor takes a walk with his old Nikon D800 for the first time in years and describes the challenges he faced to get pictures he loves.
-



-
-

Ninja Double Stack air fryer review: half the footprint, double the fun
Ninja's innovative Double Stack air fryer is designed for those with small kitchens but big appetites, and it really delivers.
-
Shark HydroVac Cordless review: a very effective vacuum-mop
We take a closer look at the cordless Shark HydroVac, to see if it can achieve spotless results with little elbow grease.
-

These air fryer Nutella toast pies are the ultimate comfort snack
Here's how to make Nutella toast pies that are the perfect snack, any time of day.
-

Siri forgot how to tell the time on the HomePod – and that shows how much it needs an AI upgrade
Siri’s HomePod-based time-telling woes are a clear sign it needs an AI upgrade.
-



-
 Updated
UpdatedThe best 65-inch TV 2024
We pick out the best 65-inch 4K TVs to complete your home theater setup, no matter how much you want to spend.
-
-
 Updated
UpdatedThe best iPad 2024
Whether you want the best iPad Pro or the best cheaper iPad, a small iPad mini or a thin-yet-powerful iPad Air, you'll find the top options here.
-
 Buying Guide
Buying GuideBest Xbox Game Pass games to play in 2024
New to the service and wondering what the best Xbox Game Pass games are? Our curated list is here to help.
-
The best 4K Blu-ray players 2024
Streaming services are popular, but there's no better way to watch movies than with the best 4K Blu-ray players.
-
Updated
Best Sony camera 2024: the top choices for both stills and video
Searching for the best Sony camera? Whether you need a full-frame powerhouse or a travel-friendly compact, we've ranked the best models in its impressive range.
-
 Updated
UpdatedThe best Android tablets 2024
The best Android tablets, from the gigantic Galaxy Tab to the pocketable Amazon Fire, we've tested the best you can buy.
-
Updated
The best 75-inch TVs 2024
The best 75-inch TVs offer a true big-screen experience, with a size befitting the greatest films and the most nail-biting sports matches.
-




Why we're experts

We care passionately about tech
The TechRadar team has a life-long passion for the latest innovations – over 300 years of experience between us, in fact – and we’ve made it our mission to share that combined knowledge and expertise with you.
We’re here to provide an independent voice that cuts through all the noise to inspire, inform and entertain you; ensuring you get maximum enjoyment from your tech at all times. Technology is our passion, so let us be your expert guide.
years' experience
how-tos written
Apple events covered
-
-
Hot deals
The cheapest OLED TV deals and sales for May 2024
Your guide to the best OLED TV deals with incredible sales from brands like Sony, LG, and more.
-

The Google Pixel 8a is here - and yes, you can already get it for free with this deal
The latest Google Pixel 8a offers a compelling array of specs for a wallet-friendly mid-range price.
-

The best iPad deals in May 2024
These are all of the best iPad deals that are available now so you can pay the lowest price for one of Apple's premium tablets.
-
 Deals
DealsBest Mother's Day sales 2024: last-minute deals from Walmart, Target and Amazon
Shop today's best Mother's Day sales with last-minute deals from Walmart, Target, and Amazon on gifts, jewelry, tech, and more.
-
Quick! The Google Pixel 8 Pro is $440 off at Mint Mobile right now - the lowest price yet
This Pixel 8 Pro deal at Mint Mobile won't last - it's the cheapest upfront price yet without the need for a pesky trade-in.
-

Best Buy launches big-screen TV sale - 8 best deals from $369.99
I've searched through the latest 4K TV sale at Best Buy and picked out 8 for the best deals I recommend buying today.
-




-
-

OnePlus Coupons for May 2024
Use these OnePlus coupons to get a better price on mobiles & accessories from the leading Android smartphone retailer.
-
Google Workspace Coupon Codes for May 2024
These Google Workspace coupon codes are here so you can make bigger savings on your plan.
-

Casper Coupons for May 2024
These Casper coupons can help you save big on your next bedding purchase from sheets, pillows, mattresses, and more.
-
Keeper Security Promo Codes for May 2024
Look through our Keeper Security promo codes to save on subscriptions to the online password manager and protect your details online for less.
-




TechRadar's story

Our mission is unchanged
TechRadar was launched in January 2008 with the goal of helping regular people navigate the world of technology. It quickly grew to become the UK's biggest consumer technology site.
Expansions into the US and Australia followed in 2012 and we are now one of the biggest tech sites in the world.
- We've been covering tech since 2008
- 17 international editions from Mexico to New Zealand
- We're a globally respected brand worldwide
-
-
Google is working on a faster Android setup process that uses Wi-Fi and a cable
A deep dive into Google’s Data Restore Tool showed two features allowing fast transfer speeds and easy file restoration.
-
The 5 subtle AI announcements Apple made at its big iPad 2024 launch event
Beneath the glitzy product announcements at Apple's 2024 iPad event, there was some uncharacteristic AI chatter.
-
Apple's new Final Cut Pro apps turn the iPad into an impressive live multicam studio
Users can watch feeds from four different iPhones although each mobile device will need the new Final Cut Camera app.
-

Microsoft might be spooked by Windows 10 user numbers - but will making upgrading to Windows 11 easier be the answer?
Windows 10 users have no excuse not to upgrade now that Microsoft is offering a better way to upgrade to Windows 11
-

-
-

Microsoft killed Redfall right before the release of a major update according to new report
A new report suggests that a big patch was in the works before Microsoft suddenly closed Redfall's developer.
-
 Buying Guide
Buying GuideThe best Nintendo Switch games to play in 2024
The best Nintendo Switch games promise hours of fun, whether that's at home or on the go.
-

Best GBA games - essential GameBoy Advance titles you need to play
The best GBA games have stood the test of time as landmark 32-bit titles that are as playable now as they were at launch.
-

Best cozy Switch games 2024 - unwind, relax, and chill
The best cozy Switch games will provide you with relaxing and warm ways to play on the Nintendo Switch, and these games are the best of the best.
-




Between them, the TechRadar team have 300 years' experience in tech journalism. Here's why you should trust them.


















-
-

Hands on: Eazeye Radiant portable monitor
A development of the transflective screen, the Eazeye Radiant, is a unique low-power design.
-

AWS enters 5G cloud market with Telefonica deal
Telefonica is set to move its core network for over a million 5G customers to AWS public cloud as the industry watches on.
-

More companies are facing ransomware threats — but at least it now seems like they're doing something about it
Firms are increasingly reaching to law enforcement for help and they're getting it.
-

OWC Jupiter Mini review
An all-in-one NAS solution that can be self-monitored and expanded without the need for an IT professional.
-



