
 Become a TechRadar Insider
Become a TechRadar Insider








Congratulations are in order. You, yes you, dear reader, have been part of something incredible. Thanks to your hard work, millions of books containing pretty much the sum-total of human knowledge have been successfully digitised, saving their texts for future generations. All because of you.
No, seriously.
You know how occasionally you’ll be prompted with a “Captcha” when filling out a form on the internet, to prove that you’re fully human? Behind the scenes of one of the most popular Captcha systems - Google’s Recaptcha - your humanoid clicks have been helping figure out things that traditional computing just can’t manage, and in the process you’ve been helping to train Google’s AI to be even smarter.
And you thought you were merely logging into some website or other.
Origins
Recaptcha (or “reCATCHA” if you prefer) started out as a collaboration by a number of computer scientists at Carnegie Mellon University in Pittsburgh, first released in 2007 - and it was quickly snaffled up by Google in 2009. The premise was as described above: by marrying up users who need to prove they are human to data that needs transcribing, both sides get something out of it.
So instead of digitising books by having one person carry out the very boring task of typing or checking a whole book manually, instead millions of people can unknowingly collaborate to achieve the same goal. Remember how it always used to be two words you had to enter? Conceivably, only one was the “real” test, and the other was a new word that was yet to be transcribed - but as the user you wouldn’t know which was which, so you’d have to attempt to do both accurately.

Recaptcha can even check its own work. By showing the same words to multiple users, it can automatically verify that a word has been transcribed correctly by comparing multiple attempts from multiple users across the world.
Amazingly, thanks to Recaptcha boxes appearing on thousands of major websites and receiving tens of millions of completions a day, by 2011 Recaptcha had finished digitising the entire Google Books archive - as well as 13 million articles from the New York Times back-catalogue dating back to 1851.
So what did Google do next, with no books left to digitise? In what was perhaps a happy coincidence, this coincided with the growth of artificial intelligence and machine learning.
Training montage
In 2012, Google started including not just words, but snippets of photos from Google Street View - making users transcribe door numbers and other signage. And in 2014, the system became all about training AI.
Essentially, the way machine learning works is that you hand the machine a bunch of data that is already sorted - say, a bunch of images of cats that you have tagged as cats, and then it uses this information to build a neural network that enables it to pick the cats out of other images. The more pictures of cats that you feed it, the more accurate the AI becomes at picking out cats from other images.

Google has countless reasons to want to train AI to recognise objects in images: better Google Image Search results, more accurate Google Maps results, and enabling you to search your Google Photos library for all of the photos you have taken of a specific object or place. Oh, and the small matter of making sure that your driverless car doesn’t hit anything. You know when Recaptcha asks you to identify street signs? Essentially you’re playing a very small role in piloting a driverless car somewhere, at some point in the future.
So it is hugely convenient then that Google has as its disposal hundreds of millions of internet users to work for it: by using Recaptcha to tackle these problems, Google can use our need to prove we’re human to force us to use our very human intuitions to build its database.

This is why currently, instead of simply throwing up some text, Recaptcha is giving users more image-related tasks: “Click all of the images of cats”, “Click all of the boxes on the grid overlaying an image that contain a cat”, and so on. For thousands of different objects.
This is a particularly useful asset for Google, as it competes with other internet giants to grow its machine learning datasets and algorithms: The more data it can analyse, the better results will be - giving its current and future products a competitive advantage.
Using AI to beat AI
Amusingly, there is only one problem with using captchas to train machine learning algorithms. What’s to stop, for example, people who want to get around captchas from using machine learning against captchas?
Last year developer Francis Kim built a proof of concept means to beat Recaptcha by using Google’s machine learning abilities against it. In just 40 lines of Javascript, he was able to build a system that uses the rival Clarifai image recognition API to look at the images Google’s Recaptcha throws up, and identify the objects the captcha requires. So if Recaptcha demands the user select images of storefronts to prove their humanity, Clarifai is able to pick them out instead.
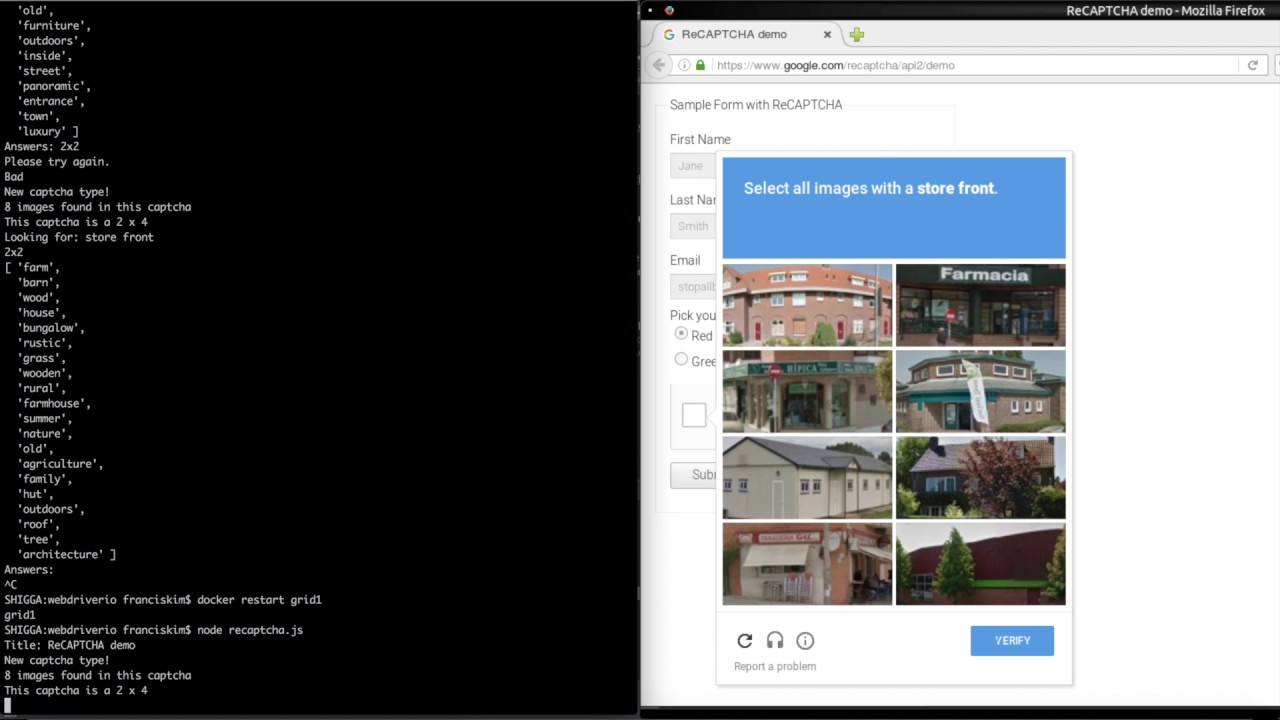
Conceivably too, this sort of thing would also be possible using Google’s own technology. Because Google wants to sell its clever tech to other companies, it opens TensorFlow up to developers through an API itself. This means that you could conceivably use TensorFlow to trick the Captcha that trains TensorFlow. This wouldn’t work 100% of the time - but once an AI is sufficiently well trained, it should be able to do the trick in a large number of cases.
What’s clear from Recaptcha is not just that it is an ingenious idea, but also that thanks to our hard work, it is getting increasingly difficult to separate us humans from the machines.
- TechRadar's AI Week is brought to you in association with Honor.