











-

7 smart home tips to help you save energy and reduce waste
Smart home devices don’t just make life easier, they can also help you save energy and minimize waste.
-
-
 Sustainability Week 2024
Sustainability Week 2024This swirly power bank might be the most sustainable battery pack on the planet
Gomi makes power banks from recycled e-bike batteries and plastic bags, with excellent repairs, for peak sustainability.
-
 Sustainability Week 2024
Sustainability Week 2024Acer shows Apple how environmentalism is done with pledge to collect equivalent of 2.5 million plastic bottles with Plastic Bank partnership
Acer is one of the best companies for living up to its green pledges – and it’s now taking on plastic waste.
-

This company just bioengineered a plant-bacteria combo to clean air better than an air purifier
Neoplants Neo PX is both a plant and an air-cleaning system
-

Brighter, low-energy OLEDs are going into production this year – but they won’t be coming to TVs just yet
New OLED displays could be twice as bright, twice as efficient and last three times longer but the best TVs won't be the first to see this new tech.
-





-
 Updated
UpdatedDeezer review
Deezer has a huge library, minimal design and good recommendations – but there’s little to set it apart from its rivals.
-
-

Lomography Lomomatic 110 review: Brand-new 50-year-old technology
The Lomography Lomoatic 110 is a 110-film camera that's simple to load and use.
-

Asus ROG Strix Scope II RX review: a keyboard for the sophisticated gamer
A top-notch keyboard with great performance and a rich feature set, the only thing that lets the Asus ROG Strix Scope II RX down is its lackluster software suite.
-

Nikon Z 40mm f/2 review: this cheap, modern 'nifty forty' has been my everyday lens for over a year and it hasn't let me down
Nikon's cheapest prime is a cost-effective entry-point into the Z mount ecosystem and a great take on the 'Nifty Fifties' of old.
-

Instant Vortex 9-quart Air Fryer with VersaZone technology review: competent, but not flawless
The Instant Vortex Air Fryer with VersaZone technology serves up a large single cooking basket that can be divided into two for fuss-free air frying.
-

Withings ScanWatch Nova review: analog looks with exceptional digital brains
The Withings ScanWatch Nova 2 is an unassuming yet powerful smartwatch and health tracker.
-

JLab JBuds Lux ANC review: budget headphones that are all about that bass
The JLab JBuds Lux ANC are the brand's first 'luxury' over-ear headphones, which offer lots of bass but a few aches too.
-







How TechRadar tests

Product testing for the real world
You need to know that the device or service you’re about to spend money on works as advertised - and that it works in the real world.
- We test properly: objective and subjective testing
- We use experienced experts for our reviews
- We always offer 100 per cent unbiased, independent opinions
reviews
hours' testing
buying guides
-

HMD steps out of Nokia's shadow and launches its own mid-range smartphone line
The Pulse phones share hardware similarities but have much different camera setups.
-
-
Sustainability Week 2024
This swirly power bank might be the most sustainable battery pack on the planet
Gomi makes power banks from recycled e-bike batteries and plastic bags, with excellent repairs, for peak sustainability.
-
 Updated
UpdatedThe best power banks 2024
Here are the best power banks, whether you're after a slim portable charger for phones or a large bank to juice up your tablet.
-

This Game Boy-styled MagSafe stand just tickled my retro-gaming synapse – now all I need is a matching controller for Nintendo emulators
This retro Nintendo MagSafe stand has me rushing for Amazon – just take my money.
-
Does closing apps on your iPhone save battery life? The surprising answer is no – here's why
Closing background apps has a negligible impact on your iPhone's battery life and performance – and Apple's confirmed it.
-

Nothing could be working on an enhanced Phone 2a and a new flagship Phone 3
Nothing could be working on two more phones, including a Phone 2a Pro model and a Phone 3.
-

Gemini AI is heading to older Android phones, and could get a new 'conversation' mode
Fresh leaks around the Gemini AI app for Android point to a new mode and support for older devices.
-






-

Asus ROG Ally gets its most important update yet: a free boost to make games run much faster
If you own one of these smart gaming handhelds, you need to grab the latest update as a priority.
-
-

Apple might start developing its own AI chips - here’s what that means for Mac lovers
Leaker claims Apple is stepping up its AI game - but don’t expect it to make a difference for the M4 chip.
-

Logitech has built an AI sidekick tool that it hopes will help you work smarter, not harder, with ChatGPT
Logitech introduces AI Prompt Builder, looking to enhance users’ ChatGPT interaction. It promises to smooth out prompts, improve workflow, and pave the way for seamless conversation.
-

AMD’s Zen 5 CPUs are ‘imminent’ and another motherboard maker seemingly confirms them as Ryzen 9000 chips
It’s looking more and more likely that we’ll see Ryzen 9000 processors early in Q3, perhaps in July.
-

Microsoft’s Surface Pro 10 may be fitted with Qualcomm's latest chip - which should Apple and Intel nervous
Microsoft’s Surface Pro 10 could come fitted with a Snapdragon X Plus chip - which promises a 10% performance bump on Apple’s M3 chip.
-

Microsoft Edge gets some Grammarly-style AI upgrades to boost your writing chops
Edge introduces AI Compose for smarter text editing, digital pen support for handwriting, and enhanced clipboard functionality, enhancing browsing productivity and creativity.
-
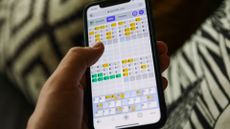
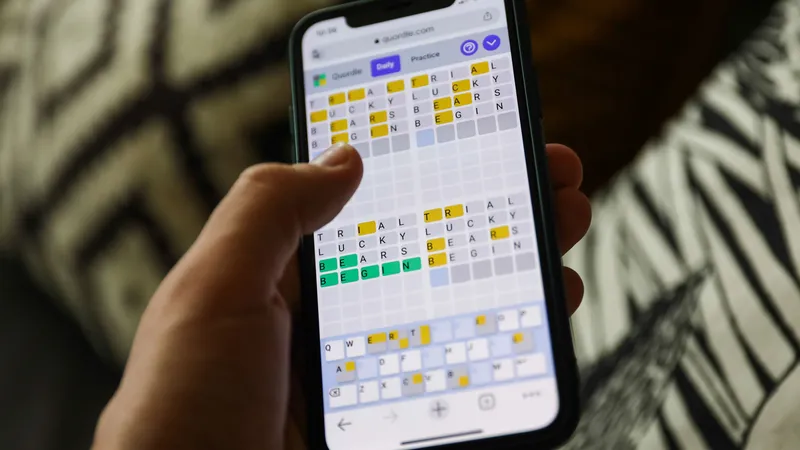
Quordle today – hints and answers for Thursday, April 25 (game #822)
Looking for Quordle clues? We can help. Plus get the answers to Quordle today and past solutions.
-






-

Apple might start developing its own AI chips - here’s what that means for Mac lovers
Leaker claims Apple is stepping up its AI game - but don’t expect it to make a difference for the M4 chip.
-
-
 Updated
UpdatedThe best cheap tablets 2024
Looking for the best cheap tablet that's actually worth buying? Whether you're after an Amazon, Android, or iPad tab, you'll find our favorite budget options here.
-
 Updated
UpdatedThe best iPad 2024
Whether you want the best iPad Pro or the best cheaper iPad, a small iPad mini or a thin-yet-powerful iPad Air, you'll find the top options here.
-

Apple sale at Best Buy - I've picked the 8 best deals on iPads, AirPods and MacBooks
Over a dozen Apple deals are now live at Best Buy so I've searched through the sale and picked out 8 of the best ones on iPads, AirPods, MacBooks and iPhones.
-

Report claims Vision Pro sales have ‘fallen sharply’ as Apple struggles to whip up demand
An Apple analyst believes Apple has slashed shipments of the Vision Pro as it has struggled to generate sales.
-





-
 Updated
UpdatedArcane season 2: everything we know so far about the hit Netflix show's return
Here’s everything you need to know about Arcane season 2 on Netflix ahead of its late 2024 release.
-
-

Zack Snyder's next big project for Netflix has been revealed, and it isn't Rebel Moon Part 3
Twilight of the Gods is confirmed to be Zack Snyder's next project for Netflix – and it'll be out before the end of 2024.
-

Netflix's Wednesday season 2 cast clicks into gear with Westworld star addition as Apple's Neuromancer series finds its lead
Some top-tier talent just joined some of our most-anticipated streaming shows from Apple TV Plus and Netflix.
-

Netflix's official Atlas trailer puts Jennifer Lopez in another generic Terminator clone, but with Titanfall-like mechs
It feels like we've seen and heard a lot of this before. Is Netflix's new Atlas movie more than its obvious sci-fi influences?
-

Prime Video movie of the day: Interstellar is Christopher Nolan's best movie
Nolan's space thriller is epic and personal in equal measure.
-





-
-

Best Buy is slashing prices on our best-rated OLED TVs - save over $1,000 while you can
Best Buy is having a huge sale on our best-rated OLED TVs, and I'm rounding up the best deals with over $1,000 from Samsung and LG.
-
 Updated
UpdatedThe best indoor TV antennas for 2024
These are the best indoor TV antennas for watching free TV channels at home.
-

How to buy a good secondhand TV, or make your old TV last longer
Buying a secondhand TV is a great way to save money and help prevent waste, but navigating it can be a bit of a minefield - we're here to help with that.
-
Brighter, low-energy OLEDs are going into production this year – but they won’t be coming to TVs just yet
New OLED displays could be twice as bright, twice as efficient and last three times longer but the best TVs won't be the first to see this new tech.
-

JMGO’s new 4K projector has a built-in gimbal so you can place it anywhere in your home
The new JMGO N1 Ultra promises to be the perfect projector for pretty much any space.
-

New Google TV 4K streaming stick tipped to land soon – and it could come with a new remote
Nearly four years after the Chromecast with Google TV 4K launched, there are rumors that a new one could launch soon.
-
 Hot deals
Hot dealsThe cheapest OLED TV deals and sales for April 2024
Your guide to the best OLED TV deals with incredible sales from brands like Sony, LG, and more.
-






-
-

The next HomePod could be more like a soundbar according to this Apple patent – and it hints at fixing the HomePod 2’s biggest issue
The next Apple HomePod might be getting an unexpected design and an exciting new addition.
-
 Updated
UpdatedDeezer review
Deezer has a huge library, minimal design and good recommendations – but there’s little to set it apart from its rivals.
-

'In the beginning I didn't want to – my son persuaded me': why Audiovector's Trapeze Reimagined speaker is a 45-year family affair
Audiovector is a Danish outift that's serious about sound, but it's also the father-and-son heartwarming hi-fi tale you need.
-

Soundcore's new sports earbuds offer a Powerbeats Pro-style customizable secure fit for a fraction of the price
The Sport X20 specializes in customization as you can adjust the hook to fit your ear and tweak its audio output.
-
 TechRadar Deals
TechRadar DealsBest Apple Memorial Day sales 2024: date and deals to expect
Your guide to this year's Memorial Day Apple sales event, with key information such as the date and deals to expect.
-

The best wireless earbuds 2024
Here are our picks of the best wireless earbuds for Android, for iPhone, or anything else you want to connect them to.
-

This Android phone for audiophiles offers a hi-res DAC, balanced output and 3.5mm jack – plus a cool cyberpunk look that puts Google and OnePlus to shame
Stylish audio brand Moondrop’s first phone is more of a hi-res digital audio player with OnePlus and Google Pixel features.
-







-
-

Fitbit users hate the recent Sleep page update, but a change could be coming
People hate the Fitbit Sleep page update, and it looks like Fitbit is taking notice; so is a change on the way?
-
 Updated
UpdatedThe best bone conduction headphones 2024
Looking for the best bone conduction headphones to keep you aware of the outside world? Here are our top picks.
-

Wear OS 5: what we want to see, and all the leaks so far
Wear OS 5 could land this year. Here's what we've heard about it and what we want from it.
-



-
-
 Buying Guide
Buying GuideThe best mirrorless camera for 2024
Our best mirrorless camera guide will help you find the perfect pick for you, whatever your budget or shooting style.
-
Updated
The best camera for photography 2024
Our guide to the best camera for photography will help you find the right digital camera for you, whatever your budget.
-
 Updated
UpdatedThe best cameras for vlogging 2024
Our guide to the best cameras for vlogging rounds up all of our top picks for on-the-move video creators, at all price points.
-
Lomography Lomomatic 110 review: Brand-new 50-year-old technology
The Lomography Lomoatic 110 is a 110-film camera that's simple to load and use.
-


-
-
 Updated
UpdatedThe best vacuum cleaner 2024
These are the fastest, quietest, smartest, most powerful vacuum cleaners for every kind of home.
-

New Google Nest Audio and Nest Hub Max devices could be in the works
Google could be working on new Nest Audio and Nest Hub Max devices, and there's potential for generative AI to be front and center.
-
This company just bioengineered a plant-bacteria combo to clean air better than an air purifier
Neoplants Neo PX is both a plant and an air-cleaning system
-
Instant Vortex 9-quart Air Fryer with VersaZone technology review: competent, but not flawless
The Instant Vortex Air Fryer with VersaZone technology serves up a large single cooking basket that can be divided into two for fuss-free air frying.
-


-
 Buying Guide
Buying GuideThe best mirrorless camera for 2024
Our best mirrorless camera guide will help you find the perfect pick for you, whatever your budget or shooting style.
-
-
 Updated
UpdatedThe best gaming PC 2024
Finding the best gaming PC for you can be tricky, with confusing spec sheets and numerous configurations - but we're here to help.
-
Updated
The best cheap tablets 2024
Looking for the best cheap tablet that's actually worth buying? Whether you're after an Amazon, Android, or iPad tab, you'll find our favorite budget options here.
-
Updated
The best power banks 2024
Here are the best power banks, whether you're after a slim portable charger for phones or a large bank to juice up your tablet.
-
Updated
The best iPad 2024
Whether you want the best iPad Pro or the best cheaper iPad, a small iPad mini or a thin-yet-powerful iPad Air, you'll find the top options here.
-
Updated
The best vacuum cleaner 2024
These are the fastest, quietest, smartest, most powerful vacuum cleaners for every kind of home.
-
Updated
The best camera for photography 2024
Our guide to the best camera for photography will help you find the right digital camera for you, whatever your budget.
-


Why we're experts

We care passionately about tech
The TechRadar team has a life-long passion for the latest innovations – over 300 years of experience between us, in fact – and we’ve made it our mission to share that combined knowledge and expertise with you.
We’re here to provide an independent voice that cuts through all the noise to inspire, inform and entertain you; ensuring you get maximum enjoyment from your tech at all times. Technology is our passion, so let us be your expert guide.
years' experience
how-tos written
Apple events covered
-
-
 Deals
DealsMother's Day sales 2024: deals from Walmart, Target, Amazon and more
Your 2024 Mother's Day sales guide with all the best deals from Walmart, Target, and Amazon on gifts, jewelry, flowers, and more.
-

AMD's flagship graphics card, the RX 7900 XTX, is under $850 for the first time ever
The AMD Radeon RX 7900 XTX, AMD's flagship graphics card, has dipped below the $850 price threshold for the first time ever.
-
Apple sale at Best Buy - I've picked the 8 best deals on iPads, AirPods and MacBooks
Over a dozen Apple deals are now live at Best Buy so I've searched through the sale and picked out 8 of the best ones on iPads, AirPods, MacBooks and iPhones.
-
TechRadar Deals
Best Apple Memorial Day sales 2024: date and deals to expect
Your guide to this year's Memorial Day Apple sales event, with key information such as the date and deals to expect.
-

Don't miss the Samsung Galaxy S23 Ultra for just $849 at Best Buy right now
Best Buy has cut more than $500 off the Samsung Galaxy S23 Ultra, bringing the price down to just $849.
-

The best laptop deals in April 2024
Our expert guide to all the best laptop deals currently available.
-




-
-

OnePlus Coupons for April 2024
Use these OnePlus coupons to get a better price on mobiles & accessories from the leading Android smartphone retailer.
-

Keeper Security Promo Codes for April 2024
Look through our Keeper Security promo codes to save on subscriptions to the online password manager and protect your details online for less.
-

Casper Coupons for April 2024
These Casper coupons can help you save big on your next bedding purchase from sheets, pillows, mattresses, and more.
-

Paramount Plus Coupon Codes for April 2024
Our Paramount Plus coupon codes can be added to your subscription to help you save on monthly streaming fees.
-




TechRadar's story

Our mission is unchanged
TechRadar was launched in January 2008 with the goal of helping regular people navigate the world of technology. It quickly grew to become the UK's biggest consumer technology site.
Expansions into the US and Australia followed in 2012 and we are now one of the biggest tech sites in the world.
- We've been covering tech since 2008
- 17 international editions from Mexico to New Zealand
- We're a globally respected brand worldwide
-
-
Apple might start developing its own AI chips - here’s what that means for Mac lovers
Leaker claims Apple is stepping up its AI game - but don’t expect it to make a difference for the M4 chip.
-
Logitech has built an AI sidekick tool that it hopes will help you work smarter, not harder, with ChatGPT
Logitech introduces AI Prompt Builder, looking to enhance users’ ChatGPT interaction. It promises to smooth out prompts, improve workflow, and pave the way for seamless conversation.
-

AI Explorer could revolutionize Windows 11, but can your PC run it? Here's how to check
AI Explorer is an exciting feature coming to Windows 11, but your PC might not be able to run it. Here's how to check.
-

Google Maps is getting a new update that’ll help you discover hidden gems in your area thanks to AI - and I can't wait to try it out
Google Maps has an upcoming AI feature that’ll make it much easier to discover new places in your town.
-


-
-

PS5's latest update brings a handy community-driven option to the Game Help feature
The latest PS5 update adds Community Game Help which captures gameplay to help players through tricky challenges.
-
 Updated
UpdatedThe best gaming VPN in 2024
I've put hundreds of VPNs to the test to find the best picks for gaming. See how NordVPN, ExpressVPN, and Surfshark compare.
-

Fallout 4 current-gen update drops today with a performance and quality mode
Bethesda Game Studios has announced that Fallout 4's long-awaited current-gen update will finally be released this week.
-
 Updated
UpdatedFallout 5 - everything we know so far
Fallout 5 is officially in development, but likely won't be here for a few years yet. Here's what we know so far.
-




Between them, the TechRadar team have 300 years' experience in tech journalism. Here's why you should trust them.



















-
-

Google Meet may finally have trumped Microsoft Teams and Zoom with its super-useful new call switching feature
No need to hang up and rejoin - new Google Meet "switch here" feature makes it easy to transfer calls.
-

DDoS, data theft, hack and leaks aplenty— why the 2024 elections could be the most targeted yet
Cyber influence and electoral disruption are all on the cards, but it's not all bad news.
-

Snowflake has a new LLM targeted at ticking off boring business tasks
Snowflake Arctic LLM is effective, efficient and more importantly, open-source, which is good news for enterprises.
-

CISOs are nervous Gen AI use could lead to more security breaches
Malicious Gen AI use is on top of everyone's mind, as hackers create convincing phishing emails.
-



